2023년도 서울특별시 부동산 가격의 속성 상관관계 분석과 이를 이용한 회귀 분석
프로젝트 개요
본 프로젝트에서는 2023년의 부동산 매매 가격 데이터를 활용하여 본 데이터 내에서 각 속성간의 상관관계를 측정해보고, 이 데이터셋을 시각화 및 선형회귀 모델을 이용하여 가격 추정 모델을 만들어 보았다. 데이터 분석에는 자치구 별 매물 갯수, 매물 가격대 별 갯수 그리고 건물의 종류(아파드, 단독, 연립 등)의 각 항목 별 갯수를 확인해보았다. 또한 “서울 열린데이터 광장”에서 제공하는 데이터는 위도와 경도에 대한 데이터가 없어 추가로 Google Map API를 이용하여 위도, 경도 데이터를 추가하였다. 마지막으로 선형회귀 분석에서는 일반 Linear Regression과 Logistic Regression을 사용하여 회귀 분석을 시도하였다. 여기서 일반 전통적인 선형회귀를 사용한 이유로, 먼저 데이터셋의 부족이 이유 중 하나이다. 해당 데이터셋은 중복되는 데이터가 많아 약 6만개의 데이터임에도, 중복을 제거했을 때 많은 수의 데이터가 줄어들었다.
데이터 수집
해당 프로젝트의 데이터는 서울시에서 운영하는 “서울 열린데이터 광장”에서 “서울시 부동산 실거래가 정보” 데이터셋을 이용하여 진행하였다. 해당 데이터셋에서는 연도별 매매가격과 주소, 건물의 정보등을 제공하고 있다. 제공하는 속성 중 실제 사용된 속성은 다음과 같다.
위의 속성에서 추가로 지도의 매물 및 금액 Heatmap 시각화를 위하여 위도와 경도가 필요하여 이를 수집하기 위해 법정동, 본번 그리고 부번을 이용하여 Google API를 이용, 이를 수집하였다. 수집하는 방법은 다음과 같다. 먼저, 각 행별로 법정동명, 본번, 부번을 이용하여 주소를 만든다. 이를 이용하여 “상도동 511-0”과 같은 주소 형식을 만들어 Google Map API에 넣게 되면 위도와 경도가 나오게 된 경우 데이터셋에 추가 수집 하였다.
데이터 전처리
본 데이터셋에서는 건물명, 건물용도, 신고구분 등 일부 문자열로 되어있는 항목이 존재한다. 이를 선형회귀와 PCA가 가능하도록 이들을 숫자 데이터로 바꾸어야 했다. 이를 위해 One-hot encoding과 같이 구별가능한 항목을 ID로 두어 데이터를 변경하였다. 또한, 학습 및 분석에서 의미가 없는 데이터를 제거하였다. 해당 데이터에는 신고한 개업공인중개사, 권리 구분, 취소일과 같이 Nan인 데이터가 많아 해당 데이터들은 분석 및 사용에 사용하지 않았다.
데이터 분석 및 시각화
EDA
해당 데이터셋은 서울특별시 25개의 구가 있으며, 지역간의 가격차와 건물용도 별 갯수가 차이를 보일것으로 가정하여 다음과 같이 데이터 특성을 분석해보았다.
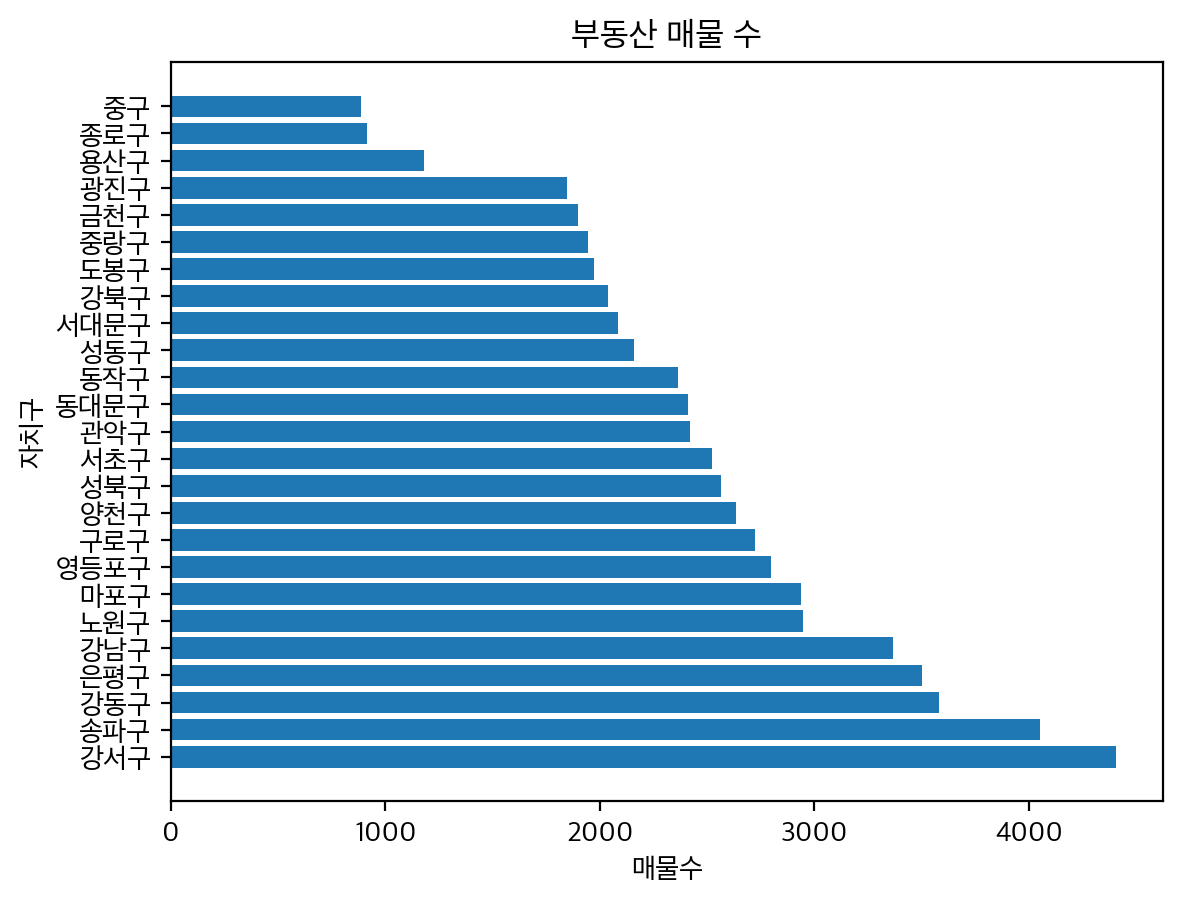
위의 차트에서는 매매 건수는 다음과 같다. 강서구와 송파구 그리고 강동구에서 가장 많은 매매가 이루어지고, 중구, 종로구, 용산구가 가장 적은 매매 건수를 보여주었다. 이는 데이터 불균형을 야기할수 있는 정도의 갯수 차이를 보여준다.
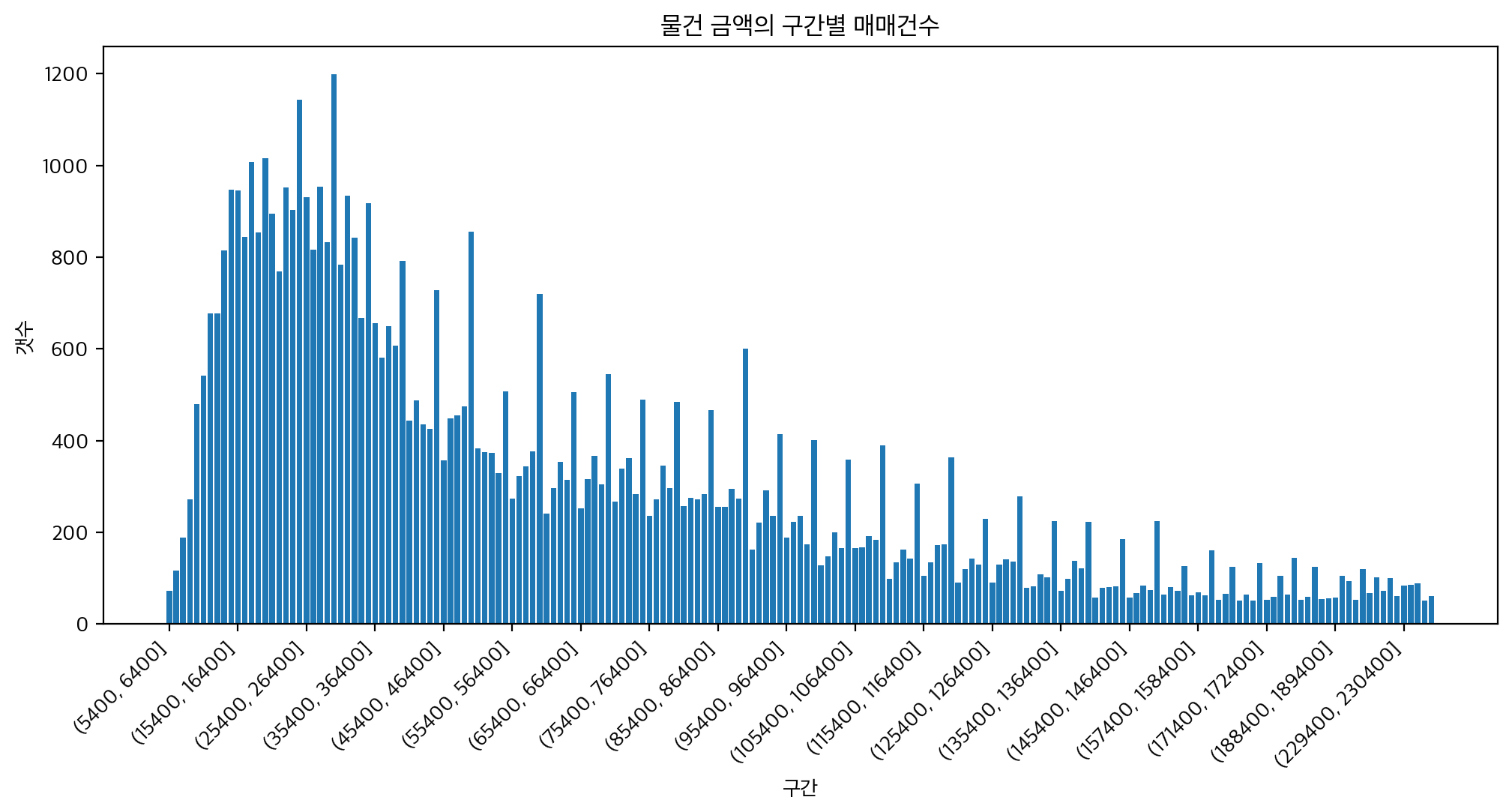
위의 차트에서는 각 100만원 단위별 매매 가격 건수를 보여주는 차트이다. 해당 데이터셋에서는 1억5천에서 4억5천 사이 금액대의 매매가 가장 활발하게 일어난것으로 보여진다. 또한, 위의 차트에서는 비교를 위해 생략하였으나, 최고 금액을 기록한 용산구 한남동 410-0에 위치한 파르크한남은 180억으로, 2위인 청담동 효성빌라에 비해 30억 정도 높은 금액을 기록하였다. 이들은 데이터 내에 잡음으로 작용할것으로 예상이 된다.
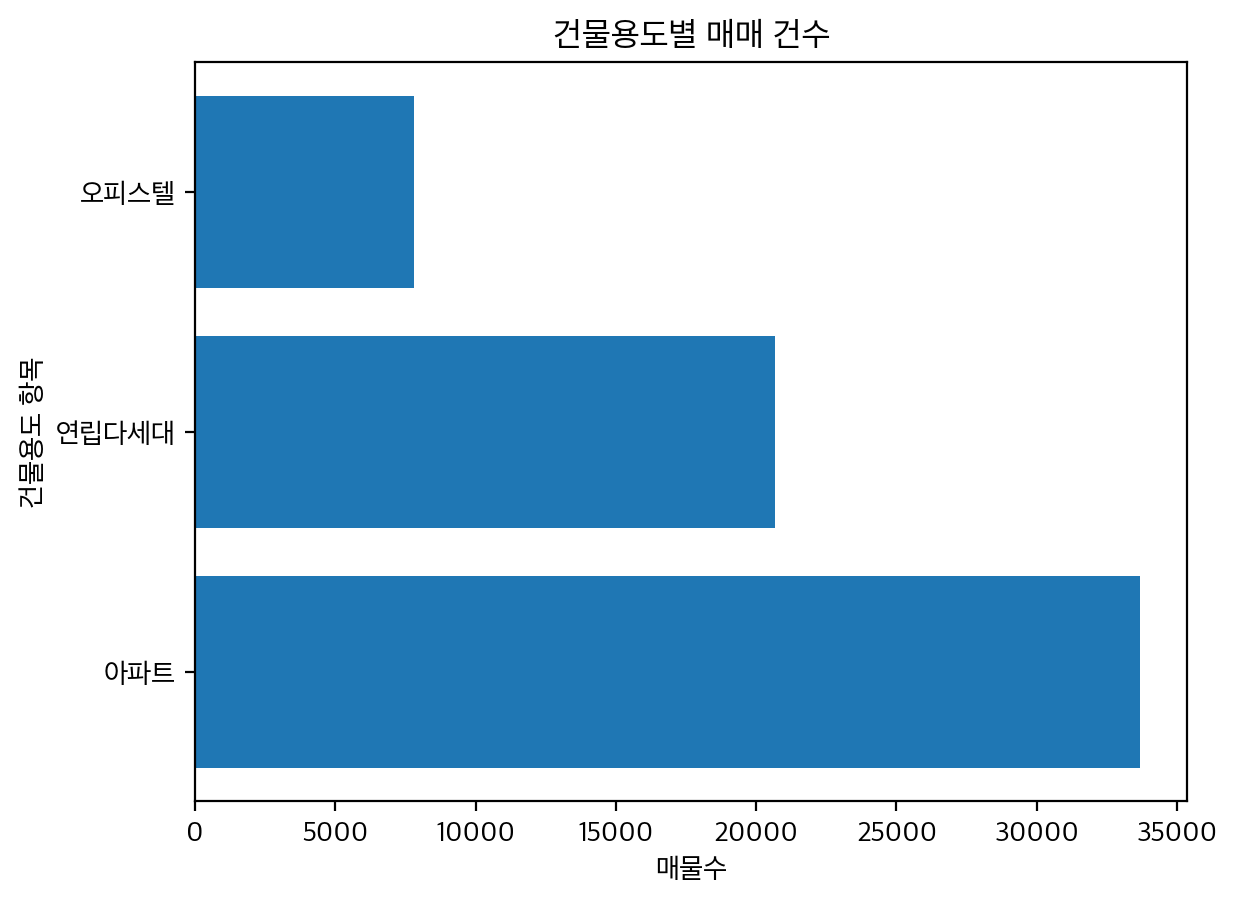
위의 차트는 건물용도별 매매 건수를 보여주는 차트이다. 해당 그래프에서 아파트가 가장 많은 데이터를 차지하며, 오피스텔이 가장 적은 수임을 볼 수있다. 이는 실제 데이터를 확인해본 결과 최근 분양되고있는 많은 아파트가 분양을 받는것도 매매로 치기에 많은 분양 아파트가 시중이 들어오고 있음으로 해석이 가능할것 같다.
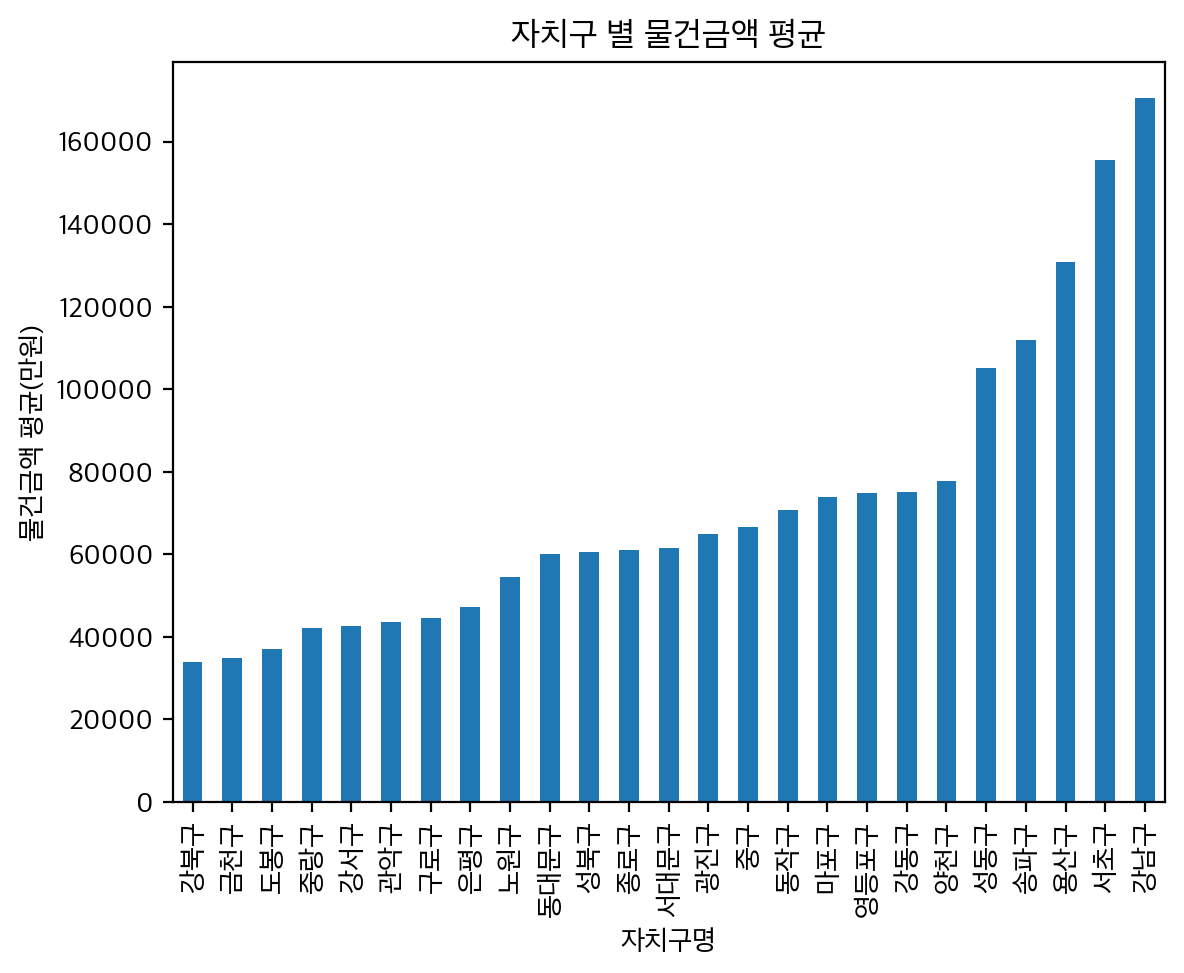
위의 차트는 자치구 별 매매금액의 평균을 나타내는 차트이다. 해당 차트에서는 용산구, 서초구 그리고 강남구가 가장 높은 금액비를 보여주며, 양천구와 급격히 가격이 올라가는 성동구간의 차가 약 2억정도 차이나는것을 보여주었다. 여기서, 매매건수가 밑에서 3번째인 용산구는 실제 매매 금액 평균에서는 상위 3번째 임을 보여주었다.
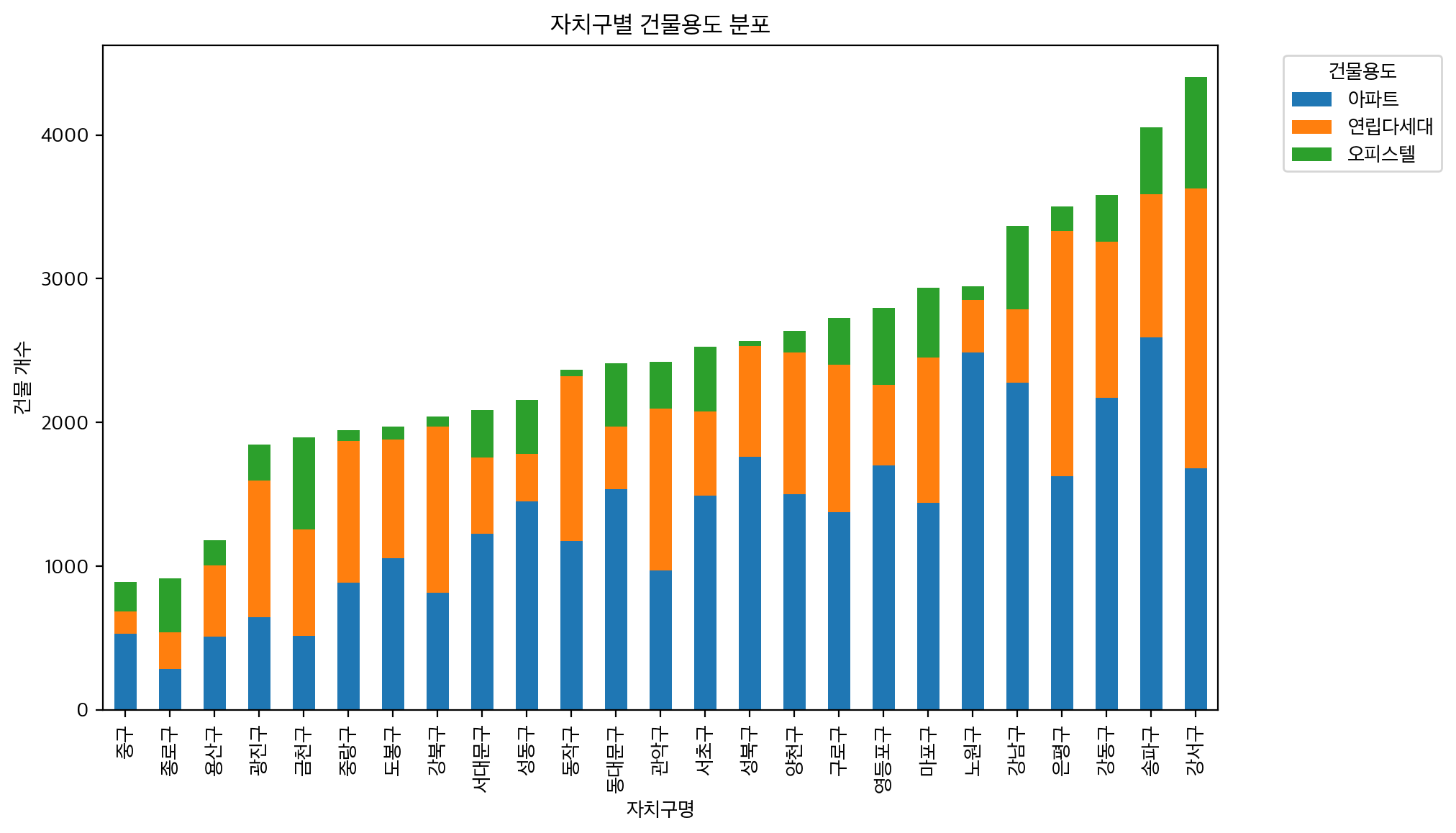
위의 차트는 자치구 별 건물 용도 분포이다. 아파트 매매는 송파구에서 가장 많이 이루어졌으며, 전체 매매 대비 노원구가 가장 많은 거래량을 보여주었다. 연립 다세대는 강서구가 가장 많았으며, 성북구가 오피스텔이 가장 적은 자치구로 나왔다. 또한 강서구가 대부분의 분야에서 많은 매매가 이루어졌음을 알 수 있다.
가격 및 매매 분포에 대한 지도 시각화
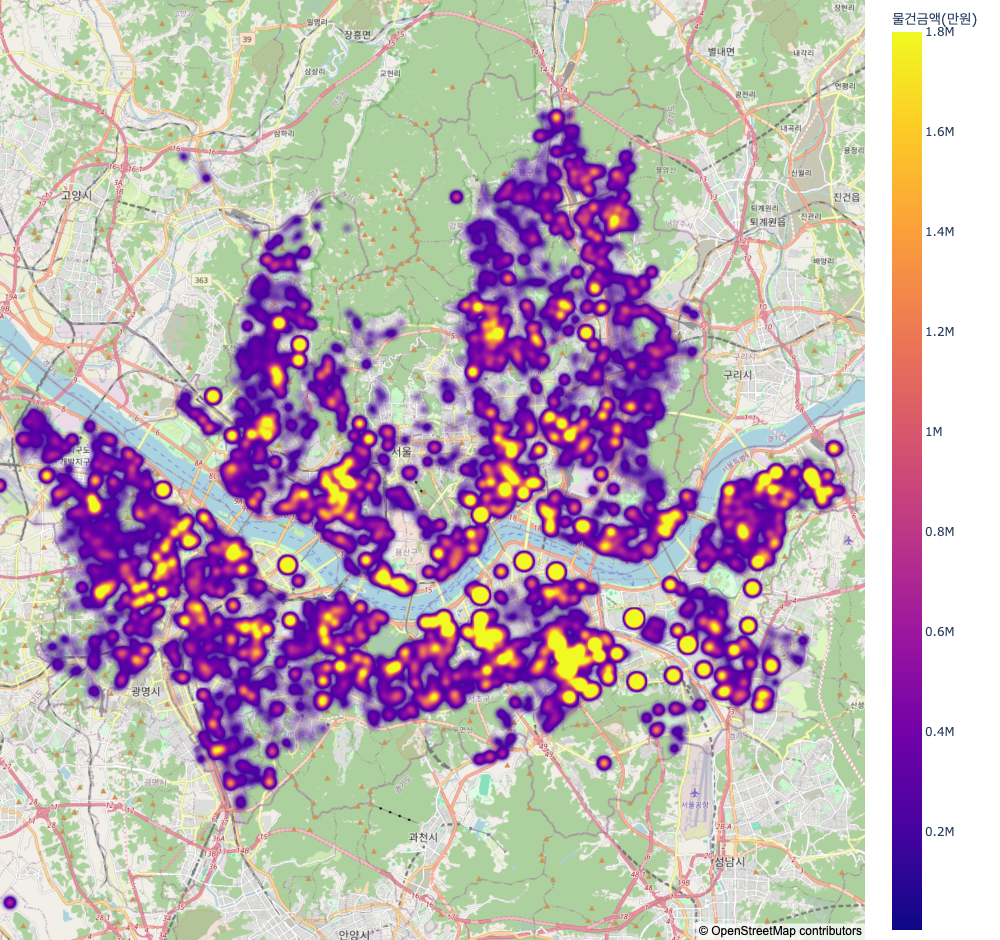
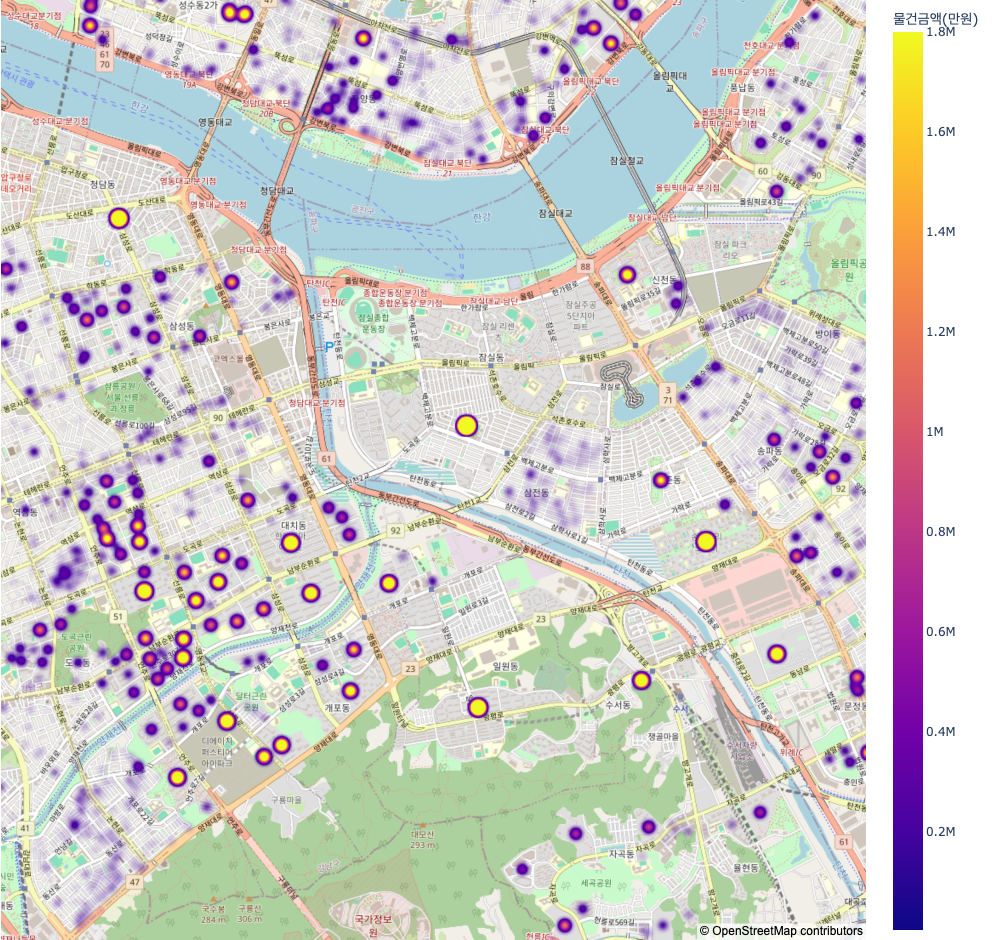
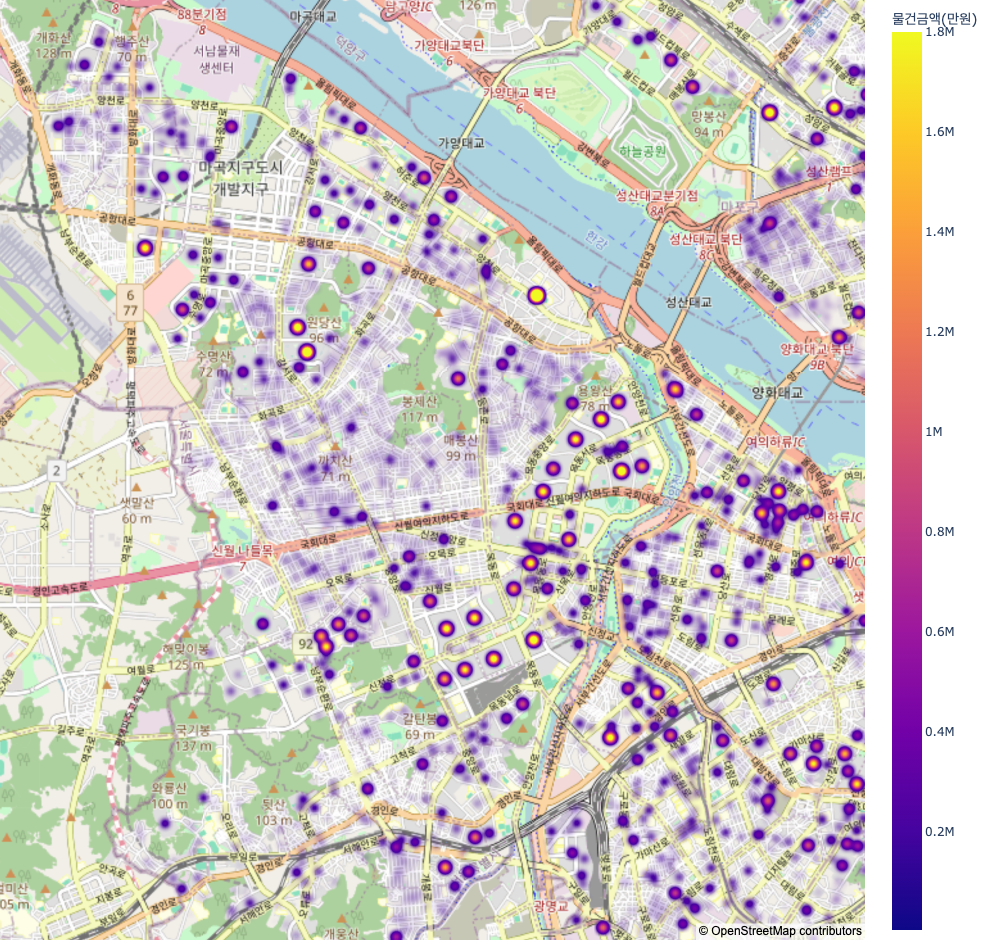
Map 1에서는 주소 데이터를 이용한 위도, 경도 데이터를 이용하여 나타낸 부동산 가격 분포 지도이다. 위의 차트 분석에서와 같이 강남구, 서초구 그리고 용산구에서 높은 가격을 보여주었다. 또한 매매 건수가 많은 강서구의 경우 대부분의 공간에서 높은 밀도를 보여주어 주택 밀도가 상당히 높은 곳임을 알 수 있다. Map 2에서는 타지역 대비 가격이 높은 지역인 강남구와 송파구 일대의 모습이다. 이들의 가격 상승 요인인 강남구 은마아파트와 송파구 헬리오시티가 아주 높은 가격을 형성하고 있으며, 나머지 다른곳에 위치한 연립다세대주택의 경우 일반 타 지역과 크게 다르지 않음을 보여주고 있다. 마지막으로, Map 3에서는 매매건수가 가장 많았던 강서구와 양천구 일대의 모습이다. 강서구의 경우 대부분의 도시 구성이 아파트보단 연립다세대 주택으로 이루어져 점들이 진하지 않게 표기되어 있음을 알 수 있다. 다만, 현재 개발되고 있는 마곡지구에서 진한 점을 보여주는데, 이곳은 개발이 되어 아파트가 있어 다음의 지도와 같이 나왔다. 양천구 일부인 목동의 경우 대부분 아파트로 구성이 되어 해당 구역이 진한 점들로 이루어져 있음을 알 수 있다.
PCA
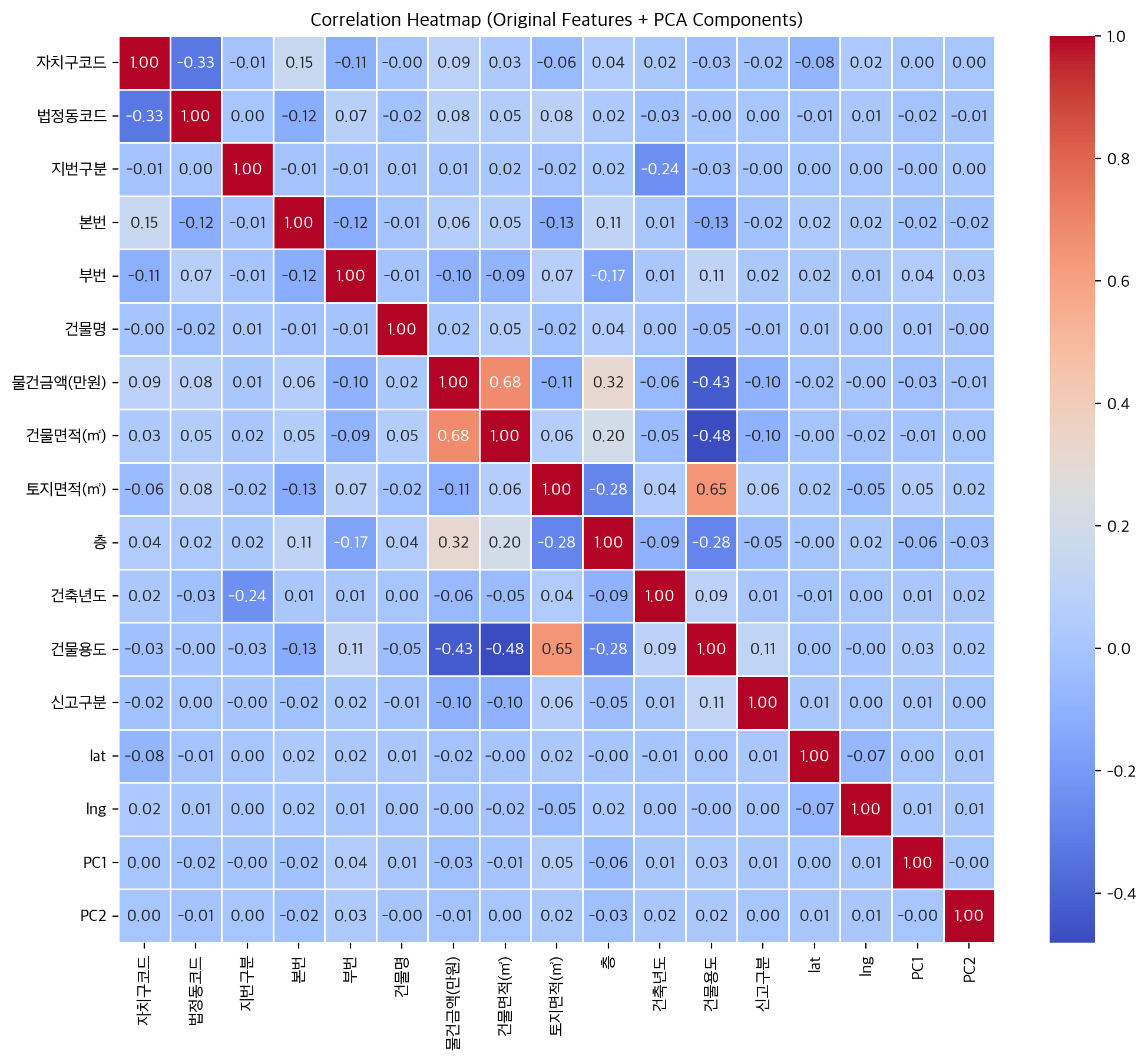
위의 PCA 차트는 건물의 금액과 어떤 요소가 가장 상관 관계가 높은지 알기 위해 구성하였다. 먼저 건물금액 부분을 보면, 가장 많은 영향을 주는것이 건물면적으로 나오게 됐다. 이는 일반적으로 생각 가능한 요소인데, 건물의 면적이 매우 중요한것과 달리 토지면적은 적은 연관 관계를 보여주었다. 이는 실제 거주시 사용하는 공간에 대해 더 중요하게 생각해 나온 결과로 해석된다. 다음으로 중요한 요소는 층수로 나왔다. 이는 저층인 주택에 비해 층수가 고층인 아파트가 더 높은 금액을 산정받아 나온 결과로 해석된다. PCA 차트에서 놀라운 점은 건물이 위치한 자치구와 법정동이 생각보다 낮게 나온것이다. 이는 위의 Map 2, 3을 보았을 때 아파트와 연립과의 금액차가 존재하여 같은 구 혹은 동에 있어도 가격차가 나기에 이것이 반영되었음으로 추측된다.
Linear Regression
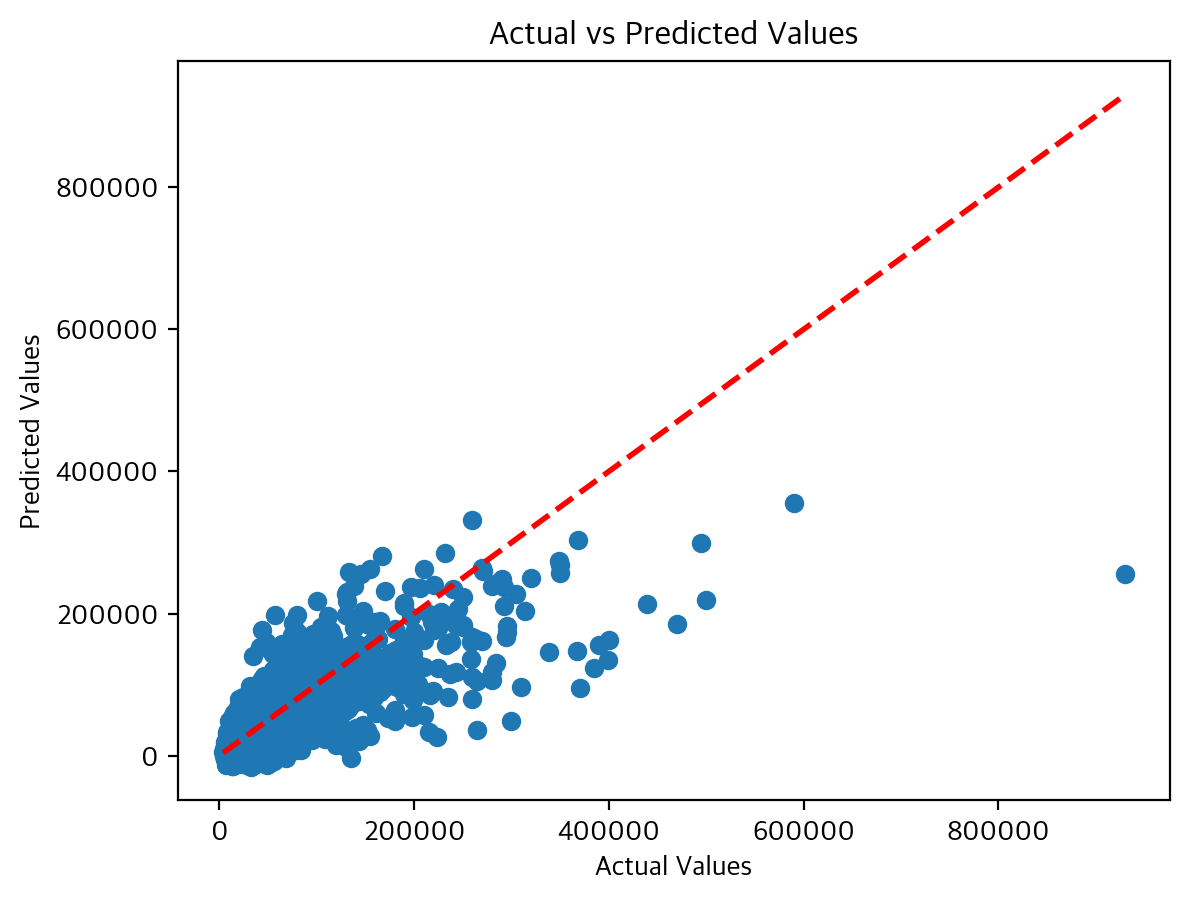
위의 그래프는 위에서 수집한 데이터를 선형회귀 모델에 입력하여 예측값과 실제 값의 정확도를 측정한 그래프이다. 위의 그래프에서 붉은 점선이 실제 데이터가 위치해야 하는 위치이며, 파란색 점이 실제 값 대비 예측된 값이다. MSE는 약 1208269786.44로 나왔으며, 모든 데이터들에 대해 표준화 진행 후 회귀를 하였다.
Logistic Regression
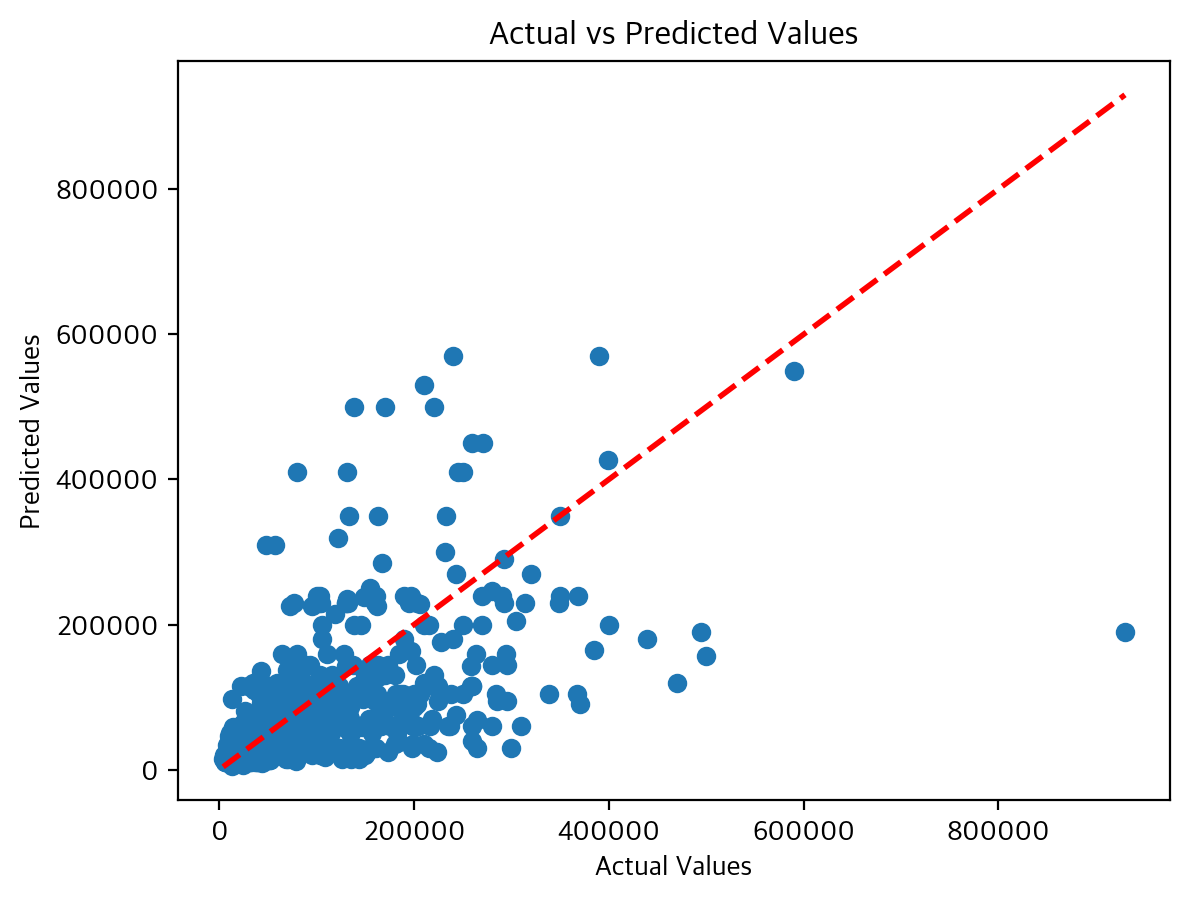
위의 그래프는 위에서 수집한 데이터를 로지스틱 회귀 모델에 입력하여 예측값과 실제 값의 정확도를 측정한 그래프이다. 위의 그래프에서 붉은 점선이 실제 데이터가 위치해야 하는 위치이며, 파란색 점이 실제 값 대비 예측된 값이다. MSE는 약 1564315131.68으로 오히려 일반 선형회귀에 비해 높게 나왔다. 실제로 위의 그래프를 대조해 보았을 때 비교적 가격을 더 높게 책정하는 경우가 많았다.
결론
이번 과제를 통해 실제로 특정 지역의 집값이 매우 높음을 수치상 확인하였다. 이는 기본적인 수치상의 차트와 매매가의 지도상의 표기로 확인되었다. 또한 지역간의 부동산 가격 격차가 최대 약 5배정도 차이남을 보여주었다. 또한, 지역별 건물용도 분포가 확연이 차이남을 볼 수 있었다. 이는 지역별로 개발정도가 차이남을 보여주어 지역별로 개발정도의 차이가 극복되어야 할 것으로 보인다. 마지막으로 PCA 분석에서와 같이 물건의 가격에는 건물용도와는 크게 상관 없으며, 건물의 실제 사용 가능한 면적과 층수가 중요함을 보여주었다. 그리고 부동산 현황 분석과 별개로, 데이터 분석의 중요성에 대해 강한 필요성을 느꼈다. 이전에는 데이터와 좋은 모델을 조합하게 되면 대부분 좋은 결과가 나올것으로 생각하였으나, 데이터셋에는 이상치와 같은 노이즈들이 존재하고, 이들을 제거 혹은 개정하여 반영하는것이 좋은 모델을 생성하는데 초석이라는 점을 다시 한번 체감시켜주었다.
해당 과제에 대해 제언은 다음과 같다. 먼저, 2023년만 반응한 결과에 대해서만 분석하지 않고, 이전 년도와 비교 및 포함하여 분석하는것도 고려해볼 점으로 생각된다. 최근 언론에서 22년도 매매가에 비해 대부분 지역에서 비교적 가격이 떨어져 이에 대한 비교도 의미있는 분석이라 생각된다. 또한, 위의 차트 분석을 지도에도 반영하게 되면 조금 더 좋은 분석이 가능할것으로 보인다. 해당 데이터는 GIS로 지도와 필연적인 연관성이 있어 지도에서의 비교 분석이 더 쉬워, 이를 적용하면 더 좋은 분석이 가능할것으로 보인다.